Retrieval Augmented Generation (RAG)
RAG, or retrieval augumented generation is one of the most popular methods of building applications on top of general large language model. It allows using the knowledge and language skills of a world-class pre-trained model, while delivering results specific to a vertical or a company.
Why RAG?
Generative AI models like GPT-3 are powerful, but they are not perfect. They can generate text that is incorrect, biased, or not relevant to the context. After all, they are trained on information from the internet, and people often post wrong, misleading or fake information. But the main limitation is that they do not have access to specific knowledge or data. ChatGPT can write an employee handbook for a company, but it cannot answer questions about the company's specific policies or procedures.
There are two popular ways to address this core limitations, and they can be used separately or together. One is to fine-tune a model on a specific dataset or task. And the other is RAG. For every question asked, retrieve the most relevant information from the preferred sources, and provide it to the generative model as context to use when responding to the question. RAG is generally cheaper, faster and lower-effort than fine-tuning, and it can be used to improve results from any generative model, so it is a popular choice for many applications.
RAG Architecture
From the short description above, you can see that the key to successful RAG is the ability to provide the generative model with the most relevant information. And this requires preparing and storing data in a way that makes it efficient (and even plain possible) to retrieve the most relevant information.
Putting together the data preparation, storage, and retrieval methods with the generative model in order to have an informed conversation with a generative model is the essence of retrieval-augmented generation (RAG). The general architecture of RAG-based application is illustrated in the figure below:
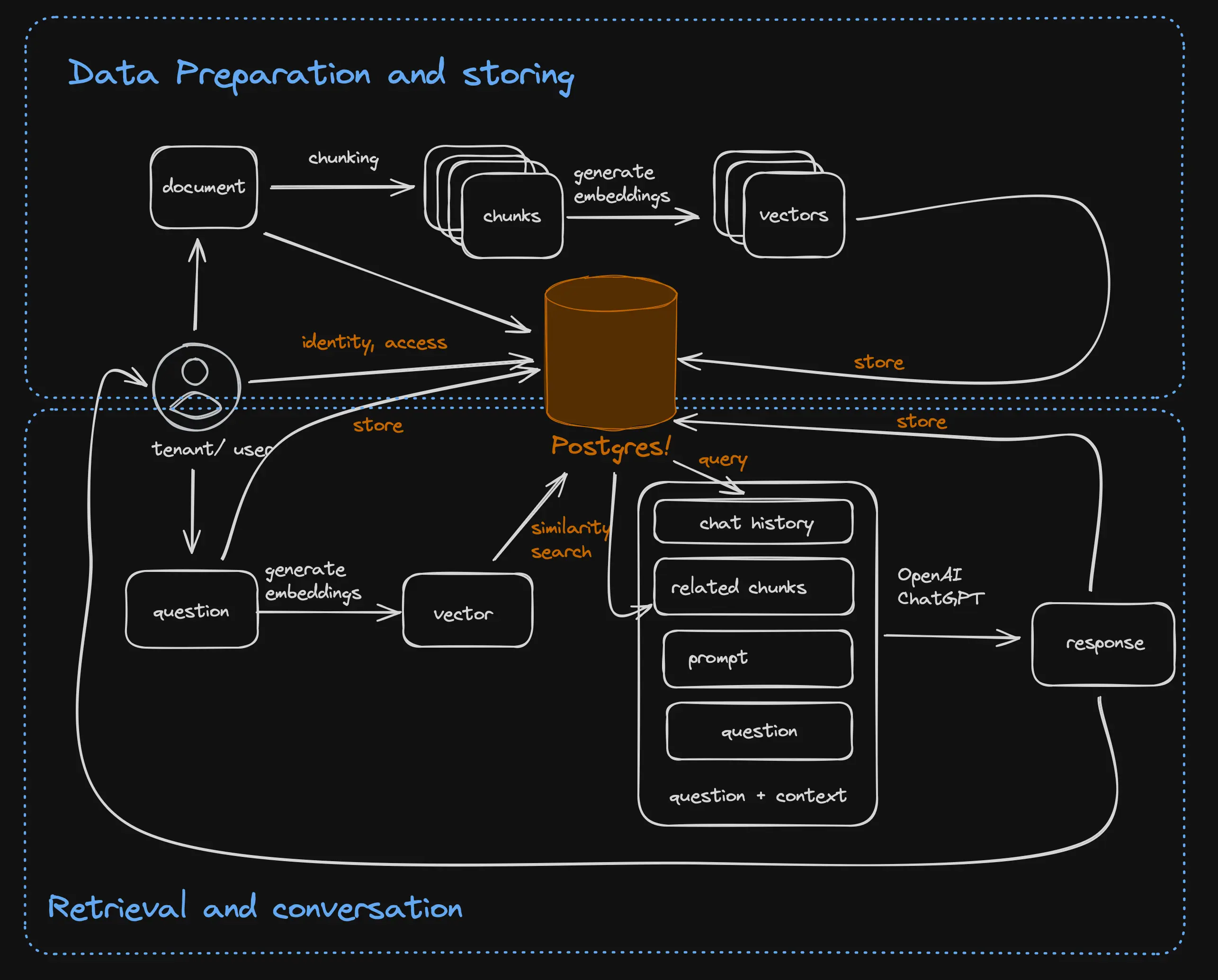
As you can see, RAG based applications typically have two independent phases:
- Ingestion phase: In which they load the source documents, split them into chunks, generate vector embeddings, store them in a database, and optionally generate an index on the stored vectors.
- Conversation phase: In which they take the user question, generate a vector embedding, search the stored vectors for related chunks, and then send the question together with the related text and perhaps older questions and responses in the conversation and a creative prompt to ChatGPT’s conversation API. When ChatGPT responds, the question and answer are stored and displayed to the user.
Lets discuss each of these tasks in more detail. We'll start with the last task, the retrieval of relevant information, since our choice of retrieval method will influence the data preparation and storage methods.
Retrieval Methods
For text retrieval, there are two popular methods, and a hybrid of the two:
Full-text search Full-text search is the more traditional approach. Text search algorithms rely on word frequency (how often the word appears in each text vs in general) and lexical similarity (The word “ice cream” is similar to “ice” and “cream” but not to “scoop” and “vanilla”). These algorithms can handle typos, synonyms, partial words, and fuzzy matching.
Vector search (also called semantic search) This method uses AI models, based on the transformer architecture, to find documents that are similar in meaning. These specially trained transformers (called embedding models or embedders) convert text to a vector (also called embedding). The vector doesn't represent exactly the words in the text but rather the semantic meaning of the text. The embedding model is trained on a giant corpus of texts (such as the entire internet), so it has “knowledge” of which terms are related. Once texts have been converted to vectors, you can check if any two texts are related by checking how close the two vectors are. When checking the similarity of texts using embeddings, it is expected that “ice cream” will be fairly close to “scoop” and “vanilla” since these words often show up next to each other.
The popular embedders are based on transformer models, fine tuned for the task of generating embeddings. There are also specialized embedding models, pre-trained or fine-tuned for specific subsets of the language such as code, legalese or medical jargon. Words like "function", "class" and "variable" will be close to each other in the vector space of a code embedding model, but not in a general english-language model.
Hybrid In the hybrid approach, you use each method separately to find the closest matching text. Then, you combine the distance score from each method (the combination is typically weighted, and the scores have to be normalized first). Then, you re-rank the results based on the combined score and finally choose the highest-ranking documents based on the combined score. There are also a few embedding models (notably, BGE-M3) that combine the two methods in the same model, and use relevancy scores from each model to re-rank the results themselves.
Storing Documents and Embeddings
Regardless of the method you choose, you will need a data store that can efficiently store and retrieve the vectors or the text based on these methods. Some data stores that specialize in one of the two algorithms, and a few offer both. Postgres has built-in full text search and extensions for both vector and text search.
Pg_vector, which is built into Nile, has an efficient implementation of vector distance metrics, so you can order results by distance (also called ranking) or efficiently find vectors within a certain distance of another vector. There are many distance metrics, and different databases support different ones, the most common ones are: Cosine distance, the most popular distance metric for text search, and dot product which is more efficient but only works for normalized vectors.
In addition, vector databases have indexes that can make searching large collections of vectors even more efficient. These indexes are different from those you are familiar with because they are based on machine learning algorithms. These algorithms find close vectors very efficiently, even with millions of vectors. But they have accuracy and memory use tradeoffs. Because of the accuracy tradeoffs (also known as recall tradeoffs, since it looks like the database “forgot” some of the data), the algorithms used in the indexes are called ANN - approximate nearest neighbors (as opposed to KNN - the accurate results you get by fully scanning the vector collection). Because these indexes use machine learning techniques, creating them is often called training. Just don't get confused: this type of training fundamentally differs from the pre-training or fine-tuning of large language models.
You can read more about the pg_vector extension and how to use it in the Nile documentation.
Preparing documents for storage and embedding
Before you can generate embeddings or create text search indexes for documents, you need to prepare them. The preparation steps depend on the document type and the retrieval method you choose. For example, if you use PDFs or HTML documents, you will need to extract the text from them. If you used scanned documents, you will need to use OCR to extract the text.
If you use full-text search you will need to tokenize the text, remove stop words and possibly chunk it into smaller portions. If you use embeddings, you will need to chunk the text, possibly normalize it and generate embeddings for each chunk.
The specific preparation steps you'll need also depend on the search or embedding model you use - size limits on the input, whether you need to pad short documents, how it handles common words, etc. Check the model documentation for the specific requirements.
Chunking is the most common step in preparing documents. It is almost mandatory for two reasons:
- Embedding models have a limit on input text size, although this is improving and popular models can often accept 4K or even 8K tokens (words or subwords).
- Providing generative models with smaller chunks that have more closely related information usually works better than providing the model with larger, somewhat relevant chunks. AI results degrade with large context windows.
Simple RAG Example with OpenAI and Nile
In this example, we will use OpenAI's GPT-3.5 model and Nile's pg_vector extension to demonstrate how RAG works. We will embed a few documents, and then search for the most relevant document to a user's question:
const { OpenAIEmbeddings } = await import("@langchain/openai");
const { Nile } = await import("@niledatabase/server");
const EMBEDDING_MODEL = "text-embedding-3-large";
const OPEN_API_KEY = "bring your own key";
const NILEDB_USER = "we use nile as the vector store, so we need a user";
const NILEDB_PASSWORD = "and their password";
let model = new OpenAIEmbeddings({
apiKey: OPEN_API_KEY,
model: EMBEDDING_MODEL,
dimensions: 1024, // we'll explain why in the next blog
});
let nile = await Nile({
user: NILEDB_USER,
password: NILEDB_PASSWORD,
});
// some documents:
const documents = [
"JavaScript is a programming language commonly used in web development.",
"Node.js is a runtime environment that allows you to run JavaScript on the server side.",
"React is a JavaScript library for building user interfaces.",
];
// embed documents
let vectors = await model.embedDocuments(documents);
// store embeddings
await nile.db.query(
"CREATE TABLE IF NOT EXISTS embeddings (id integer, embedding vector(1024));"
);
for (const [i, vec] of vectors.entries()) {
await nile.db.query(
"INSERT INTO embeddings (id, embedding) values ($1, $2)",
[i, JSON.stringify(vec.map((v) => Number(v)))]
);
}
// now lets ask a question
let question_vec = await model.embedDocuments(["Tell me about React"]);
// search for the nearest document by cosine distance of embedding
let answer_vec = await nile.db.query(
"select id from embeddings order by embedding<=>$1 limit 1",
[JSON.stringify(question_vec[0])]
);
// return the answer:
console.log(
"based on your question, this document is relevant: " +
documents[answer_vec.rows[0].id]
);
As you can see in the example, each step in RAG is simple and can be implemented in a single line of code - embedding, storing, and searching. But the result is powerful and allows you to build AI-native SaaS applications that can answer questions about specific topics with greater accuracy, like a human expert would.
RAG best practices
Use cases for RAG
RAG performs best when:
- You have more source material than can fit in the generative model's context window.
- You have a large number of questions that can be answered by the source material. So you can embed and index the source material once and then use it to answer many questions.
- The source material is structured or can be chunked into smaller parts that are relevant to the questions.
Here are a few examples of use cases where RAG can be very useful:
- Customer Support Automation: RAG can be used to automate customer support by providing answers to common questions. The source material can be product documentation and previous support tickets.
- Sales Enablement: RAG can be used to generate custom responses based on a vast repository of sales documents, case studies, and product specifications. This allows sales representatives to quickly address potential customer questions and objections
- Knowledge Management: RAG enhance the company's internal knowledge base with a bot that can generate answers by pulling information from internal documents, wikis, and databases. This helps employees find the information they need quickly.
- Legal Research: RAG can be used to quickly find relevant legal documents, case law, and statutes to answer legal questions.
- Medical Diagnosis: RAG can be used to provide doctors with relevant medical information, research papers, and case studies to help diagnose patients.
- Code Generation: RAG can be used to generate code snippets based on a repository of code examples and documentation.
- Content Creation: RAG can be used to generate content based on a repository of articles, blog posts, and other written material.
- Product Development: Use RAG to retrieve relevant information from past project documentation, market research reports, and customer feedback.
Use cases where RAG is not the best choice
RAG is a powerful tool, but it is not always the best choice. There are two main cases where RAG is not the best choice:
When the source material is small and will be used once: For example, if you need the model to format few paragraphs of text in a table or diagram. Or you want to turn a short blog into a series of tweets. It will be faster and just as accurate to simply provide the text to the model.
Summarization: If you need to summarize a large document, RAG is not the best choice. The retrieval methods will not be able to find relevant chunks with a question like "summarize this document". And the summary generated by the model will be based on a few random paragraphs from the text. There are summarization models that were specifically trained for this task.